LA P450 Diversity Meeting August 21, 2002 David Nelson
From Chamydomonas to rice: the evolution of green P450s.
(no link)
Genomic sequencing is creating raw sequence data at a tremendous pace.
The number of eukaryotic genomes is leaving the single digit range and with
that come many new P450 sequences. My website is
dedicated to cytochrome P450 nomenclature and evolution. Since the
nomenclature is based on sequence relatedness, the names mean something
and are useful for rapid comparison across species, across phyla and
sometimes across Kingdoms. In Japan last month I talked about human and
Fugu P450s. Today the title of my talk is From Chlamydomonas to rice: the
evolution of green P450s. I will begin with Chalmydomonas, move on to
rice and in the process we will run into Arabidopsis, but I will let Soren Bak
do the honors for Arabidopsis. (no link) I chose
Chlamydomonas because all green plants evolved from a single celled green
algae over 430 million years ago. For perspective, tetrapods (that’s us)
diverged from ray-finned fishes about 420 million years ago, so fish and
humans are about as far apart as green algae and rice. If we want to
understand the origins of Plant P450s, we must look at green algae and
Chlamydomonas just happens to have a genome project and an EST project.
I should say that there are several other labs involved
in this, not just JGI. The ChlamyEST database is located at Duke and there
was an EST project at Kazusa Japan, and some BAC clones were being
sequenced at the University of Oklahoma.
There are some detectable P450s in Chlamydomonas, but the whole genome
is not yet searchable. What I could find from searches of the ESTs, BAC
ends and sequences in Genbank were 15 sequence fragments from P450s,
but no full length sequences. Looking at the C-terminal half only, there are
at least seven p450s in Chlamydomonas, but this is a minimum count, since
some of the N-terminal sequences may belong to other P450s. This number
is bound to go up, but probably not by a factor of 10. So Chlamydomonas
has a dozen or at most a few dozen P450s, not anything like Arabidopsis.
What is there? CYP51 is present as expected for a free living eukaryote. If
diet supplies the needed sterols, some eukaryotes have lost the CYP51. It is
not found in C. elegans, Drosophila or more recently Ciona (the sea squirt).
However, it is not possible for plants to lose CYP51 because they have to
make everything from scratch. In addition to CYP51, CYP97 is present.
There are both 97A and 97B-like sequences that are also seen in
Arabidopsis. The last recognizable sequence is CYP711, named in
Arabidopsis. (no link) We really do not know what the CYP97
and CYP711 sequences are doing, But they are ancient versions of the P450
enzyme. CYP711’s best animal match is CYP5 or thromboxane A2
synthase, which is closely related to CYP3, so 711 may share a common
ancestor with the CYP3 family. CYP97 clusters near the CYP4 clan in
animals, so it might be related to an ancestor to CYP4. CYP97 has also been
seen in diatoms which are Stramenopile protists, so CYP97 predated the
divergence of the crown group of eukaryotes. Because these sequences
evolved so early, they are probably doing some fundamental biochemistry
present even in single celled eukaryotes. They would be important targets
for analysis.
The other CYPs in Chlamydomonas are too different or too short to
recognize by family. We will have to wait for the genome sequence
promised this summer.
But we do not have to wait for rice. (no link) The rice genome has
been sequenced by four projects. Syngenta in Switerland, Beijing Genomics
Institute in China, Monsanto and the Rice Genome Project international
consortium in Japan. Syngenta is private so you have to sign legal
agreements to see the data. Monsanto has a similar arrangement, but they
have given their data to the Japan consortium, where it is being released
slowly as finished contigs. The Beijing group published in Science in April
and their data is blast searchable at NCBI. They are more complete than the
public project, but the reads are shotgun assemblies and there are a few
problems associated with that. The public project should reach phase 2 high
quality draft sequence for the whole genome by the end of this year.
I have spent many hours assembling and annotating the P450s from rice. As
of this past Sunday morning I was able to get the sequences sorted in family
bins and named. There is still some work to be done to complete all the
genes and finalize the naming, but I do have a gene count. You may think I
am joking, but I assure you I am not. There are approximately 452 P450
genes in rice. Some of these are only named to the family level and they still
need to be broken down into subfamilies, but that will follow soon. I
remember speaking at the 3rd Biodiversity meeting in Woods Hole in 1995
where the title of my talk was 450 cytochrome P450s. That was all that was
known then. Now we have that many in a single genome.
The last count of named plant P450s from May 16, showed
607 named sequences (not counting alleles). The total for all species was
1925 named genes, so plants represented 32%. Now with the addition of
names for the rice P450s there will be 452 more named plant sequences for a
total of 1059 from plants and 2377 total. Plants are now 45% of the total.
Also please note that all these (452/2377) genes were named in the last
month. That is about 20% of all named P450s.
How were these sequences found and how accurate is the count? The
sequences were found by blast searching. To cover the P450 sequence space
at least one sequence from each P450 clan was used. There
are 10 P450 clans in plants that include 53 P450 families. The first sequence
from a P450 clan usually gives new hits not seen with other P450 sequences.
The percent identity detectable in a single search is fairly low so sequences
can be detected from other plant clans. More than one sequence was used
from the larger clans, and the number of new hits recorded was monitored
with each search to see if additional searches were needed. Toward the end
of the search process each new search only retuned 4-6 new accession
numbers and these were all short fragments, often pseudogene pieces. This
process was carried out first on the Japonica data in Genbank. After April 5,
the same process was done on the indica subspecies data.
The sequences, initially from japonica, and later from indica were placed on
a P450 blast server at the University of Tennessee .
This server was set up by Rob Edwards, a Linux and bioinformatics
afficionado in our Department. I often update the sequences on the server
when doing this type of genome work on an hourly basis to get the new
sequences into the Blast server. Here you can search 14 different sets of
P450s from 13 species. From this server, indica sequences were compared
against japonica to find orthologs. Here is a
sample of the comparison between the P450s. The first column is the indica
accession number. a, b, c after the accession indicates multiple genes on a
single accession in order of appearance. $FI is shorthand for full length
indica sequence. I use the $ because it is a unique character that can be
counted in a word processor very easily. So the number of $FI = the number
of full length indica sequences. Orth means ortholog followed by the
accession number of the ortholog and its status. i means incomplete $PI
means pseudogene.
By making this type of table it was possible to tell if a sequence was
complete, if it had an ortholog and if one sequence was incomplete and its
ortholog was complete you could use the ortholog for additional blast
searches to find the missing sequence. It was also possible in some cases to
construct a complete hybrid sequence from two incomplete orthologs. Since
they are 99% identical this can be used in tree building.
The sequence discovery phase resulted in 545 accession numbers for the
indica P450s and 762 japonica P450 sequences or fragments on 628
accession numbers. The sequences from japonica were done earlier and they
were assembled into contigs by blast searching all fragments against the
others to find overlaps. This resulted in 341 japonica sequence contigs and
452 total sequences from both subspecies.
To name the sequences I did blast searches with one named member from
each P450 family and in the cases of large families like CYP71, I used
members from different subfamilies. I tried to use rice, sorghum, corn or
wheat sequences when available. This identified the sequences to the most
similar family, but not always to a known subfamily. The sequences were
then put in family bins and in some cases subfamily bins. At this step I used
a fairly strict cutoff of about 45-46% identity. Starting with 543 indica
sequences, after searching these with all 53 plant families, I only had 267
identified to family and 276 not assigned. That was a lot of unassigned
sequences, so to get an idea what was going on I decided to make a tree of
the full length or near full length sequences, using clustalW and Phylip. I
went through the set of 276 and deleted all partials that would affect the tree
making process and kept about 100 sequences. After a first pass to remove
sequences that were behaving in odd ways, the second generation tree is
shown here . These were all unnamed rice
sequences.
{kind=link}
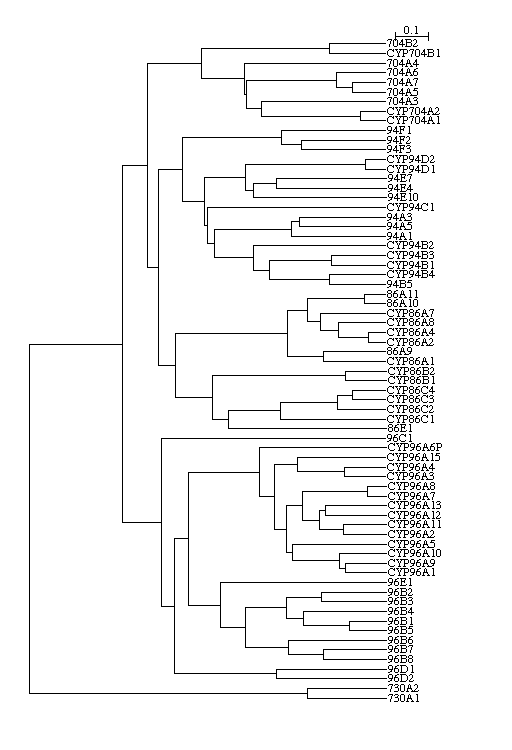
The sequences are clustered in three groups. The top was the 86 clan with
CYP86, 94, 96 and 704 members. The bottom is the 85 clan and in between
is one large group. All these sequences were unnamed and I thought I had
come across a unique rice set of P450s not belonging to the known families.
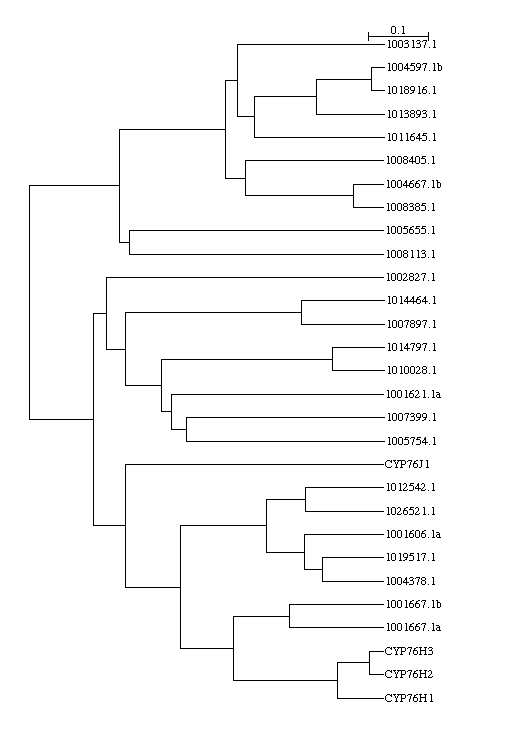
That turned out not to be true. [Slide 12 plant group A] Here is a section of
a larger tree showing the CYP85, CYP86 and plant group A clans. After
doing another tree with one member from each of the families in the plant
group A added I found the following result. The
vertical red bars represent the plant group A sequences. The rest are all from
rice. By looking at this tree it was possible to place all the rice sequences
except for the top two and the bottom six, in existing families, which I could
not do before by using the blast results. Most of the new sequences fell in
the labeled families. 36 were in CYP71, 11 were in CYP76, 11 more fell in
the 86 clan (at the top). Only three new families were created, the very top
branch which may belong to the 86 clan, and the two lower deep branches
that belong in the 85 clan.
{kind=link}
Based on the this tree and some more detailed trees of smaller regions like
the 71 family by itself, the 76 family and the 86 clan,
names were assigned. Remember that I only used 90 unidentified
sequences to start this process and some were removed for tree building
reasons. That left about 200 shorter sequences still to be identified.
However, after all the new subfamilies were created by this tree building
process the 200 could be blast searched against the full length sequences in
the tree to get an ID. There were 16 new subfamilies created in the 71
family. This second series of blast searches identified all but 10 sequences
down to the family level. Three new families were created in the process for
a total of 6 new rice P450 families. Three of these are in the CYP85 clan.
{kind=link}
{kind=link}
{kind=link}
The ten unnamed sequences are still too short and need completion of the
genome to finish them or identify them as pseudogenes. 293 of the rice
genes are full length either in indica or japonica. I will be making a
complete set of these available for download and for blast searching on the
home page.
I would like to finish by making a comparison to Arabidopsis, since I am
sure that this is going through your minds now. What I will do is show you
tables of the P450 families with the number of genes given in rice and
Arabidopsis. That way expanded families will be obvious. Dramatic
differences are highlighted in red. (these last tables are only on the laptop right now)
The CYP51 family in rice has expanded to 13 sequences compared to 2 in
Arabidopsis. These will require the introduction of subfamilies in CYP51,
something I have been avoiding in the past. Rice has greatly expanded the
71 family with 111 vs 54 sequences. These form 16 new subfamilies in the
71 family. CYP76 is also expanded. Arabidopsis is not always the lesser in
these comparisons. Arabidopsis has more CYP79 sequences and 5 CYP82s
where rice has none. The CYP85 clan includes 87 and 90. These two
families have significantly more sequences than Arabidopsis. Two new
families appear in rice CYP728 and 729, that belong in this clan. Rice
appears to be doing a lot of biochemistry with these related enzymes. At
least CYP85 and CYP90 are involved in brassinosteroid metabolism. The
86 clan is expanded in rice but only in the CYP94 family, CYP86, 96 and
704 are nearly the same.
Note that 92 has 16 members in rice but 0 in Arabidopsis. 92 is seen in
Tobacco, so it will be curious to know what happened to this family in
Arabidopsis. On the flip side of that coin, Arabidopsis has 8 702 and 33 705
members while rice has none.
38 P450 families are seen in both plants, so these families existed before the
monocots diverged from dicots 150MYA. Two others are probably
nomenclature errors CYP99 clusters inside the CYP71s now and CYP712 is
probably a CYP705 subfamily. This suggests that most of the present day
P450 families were in place early on in the history of flowering plants.
My last slide is this plain picture of a bowl of rice. To borrow from eastern
philosophy, this picture of rice is not satisfying, not like eating the actual
bowl of rice. Genomes of rice or any other species are like pictures of a
bowl of rice. They are not satisfying until experienced by annotation. So go
get your chopsticks.