Woods Hole, Mass. talk Oct. 4, 2002
2.7 Billion years of eukaryotic P450 evolution
David Nelson
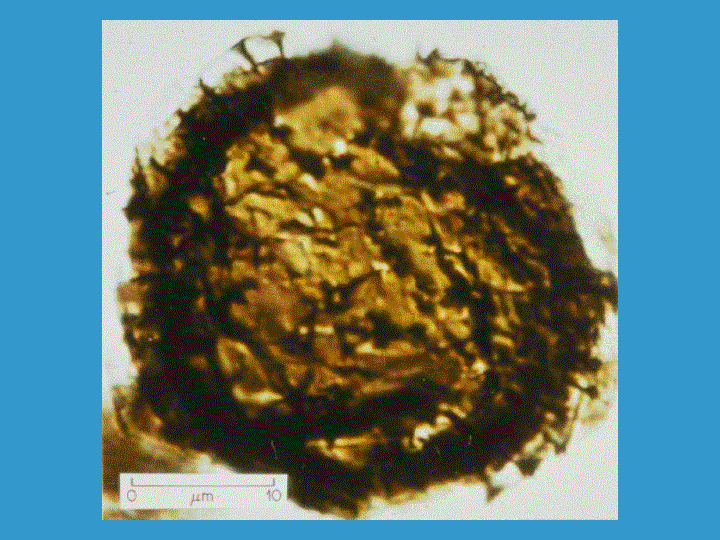
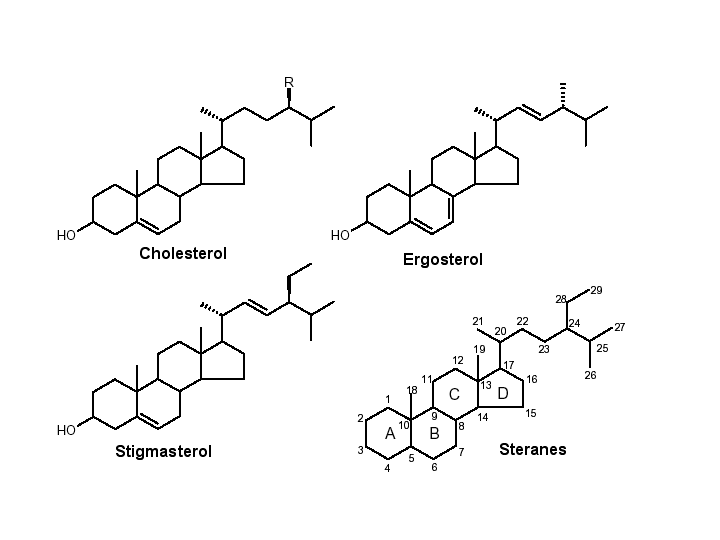
Determining the age of eukaryotic life on earth had been limited in the past to finding eukaryotic microfossils. Algal microfossils called acritarchs are seen around 1.8 billion years ago and more tentative eukaryotic microfossils have been claimed to be 2.1 billion years old. That was the oldest evidence for eukaryotic life until 1999. Then, it was reported in a Science article that eukaryotic lipid derivatives called steranes had been found in Australian shales dated to 2.7 billion years. Steranes derive from sterols, that are uniquely the products of eukaryotes so steranes are eukaryotic biomarkers. These molecules have the 4 fused ring structure of cholesterol and related lipids but they are lacking all double bonds and the 3 hydroxyl is gone. This finding pushed back the standard date of the first appearance of eukaryotes by almost a billion years.
{kind=link}
{kind=link}
Cytochrome P450 evolution is tied to this discovery also because an early step in the synthesis of sterols is the removal of a 14 methyl group. This oxygen requiring step is catalyzed by the P450 CYP51, the sterol 14 alpha demethylase. Another P450, CYP61 is the C-22 desaturase of fungi that creates this double bond. CYP51 is found in plants, animals, fungi, trypanosomes, diatoms and even Mycobacterium tuberculosis, though what it is doing in Mycobacterium is unknown, because Mycobacterium is not known to have any sterols. Because CYP51 is the only P450 found in all main branches of the eukaryotic tree (except anaerobes), it has been proposed to be the original eukaryotic P450, with all others deriving from it. The origin of CYP51 is lost. There is no clear link to bacterial enzymes that have the same function. Though it woud be desirable to trace the P450 superfamily into the bacteria, this does not seem possible now. That is why I limited this talk to eukaryotic p450 evolution.
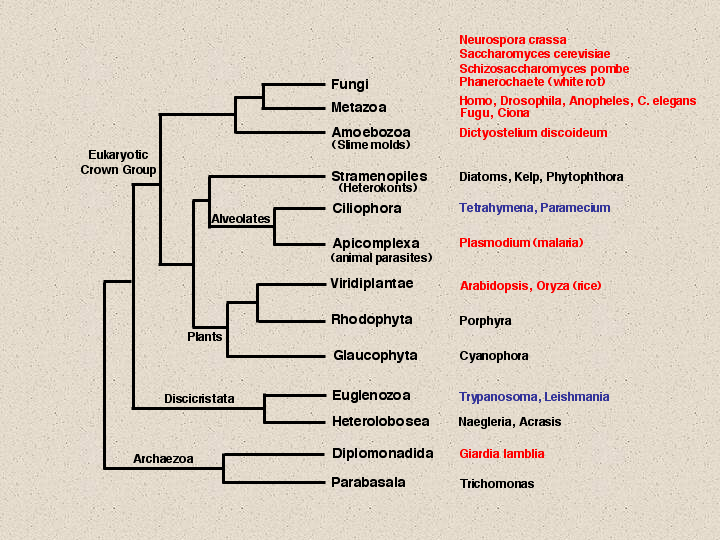
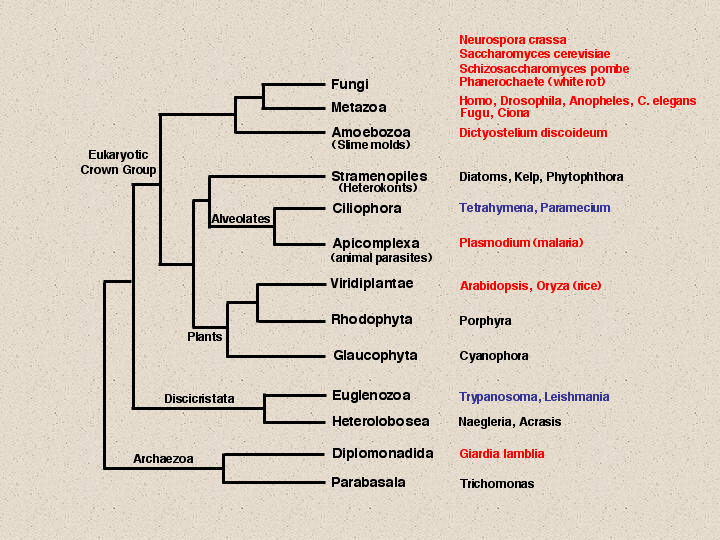
In 1987 I published my first paper on P450 with Henry Strobel. This was in the days before the dash was removed from the name and before the nomenclature system was started. This paper showed a P450 tree with 34 sequences, all that were known at the time. Today there are about 2400 named P450 sequences. These are a result of the many genome projects that have been carried out since 1996 when yeast was finished. This slide summarizes the genome project coverage of eukaryotes. Red names indicate completed or nearly completed genomes, blue names have genome projects proposed and perhaps some EST or BAC end sequencing has been done, but they are not so far along.
{kind=link}
{kind=link}
{kind=link}
Fungi have four genomes listed, Aspergillus, Fusarium and Candida albicans could probably be added to these, but the data may not be publically available. Animals have six genomes shown, mouse and zebrafish will make eight. Dictyostelium is just below animals and fungi. This genome is almost done.
You may notice that I link plants to alvelolates and stramenopiles, instead of closer to animals and fungi. I do this because of a unique 5 aa insertion in the enolase gene that is only shared among these three groups. There is actually another 1 aa insert just upstream of this that is also limited to these organisms. The Stramenopiles include kelp, which looks like a plant, but is not. Tetrahymena and Paramecium are free living ciliates in the alveolates with genome projects that are just beginning. Tetrahymena has about 10,000 ESTs in Genbank, mostly from this year. Paramecium has about 3200 Genome Survey Sequences.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Plasmodium falciparum, a parasitic alveolate and the malaria causing organism, has a finished genome. Plants now have two complete genomes, rice and Arabidopsis, a monocot and a dicot. I have just finished naming the rice p450s. Rice is the current record holder for the most P450s at 458 sequences. At least 309 of these are full length and that number will rise to about 325 as the rice genome is finished. Outside the crown group of eukaryotes there are projects mostly on pathogens like Trypanosoma and Leishmania. And of course here at Woods Hole, Giardia has been done.
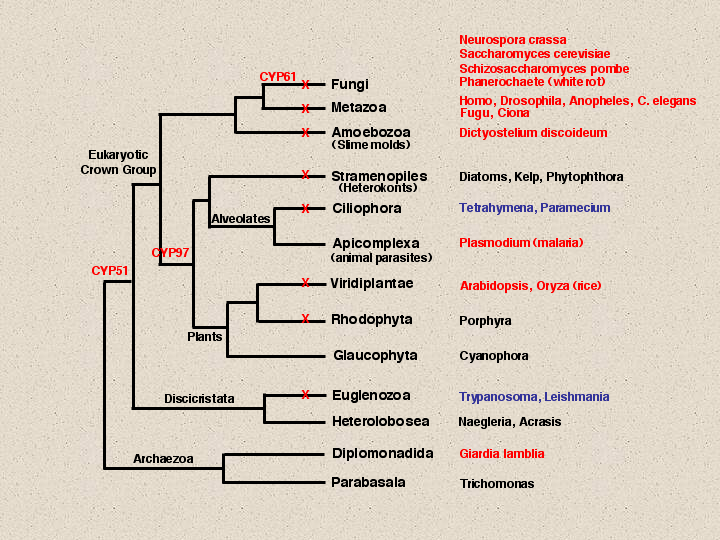
The genomes that have P450 sequences detected are maked with a red X. Notice that Plasmodium has no P450s detected by blast searches. This is a parasite that lives in a rich environment, so it has stripped down its genome and jettisoned all its P450s. Its cousin, the free living Tetrahymena does not have this luxury, and so far, one p450 has been found in Tetrahymena that most resembles a CYP4V sequence. One warning to those who want to blast search for genes in Tetrahymena. Ciliates use a different genetic code so when translating and blast searching you must be aware that TAA and TAG will be glutamines instead of stop codons.
{kind=link}
Glaucophyta and Heterolobosea have no detected p450s, but that is probably a sampling problem. I expect they will have p450s. Giardia does not seem to have a p450, but it is anaerobic and p450s usually use oxygen. No anaerobe to date has had a p450 found in its genome. Both trypanosoma and Leishmania have CYP51 genes. That is why CYP51 has been placed at almost the deepest branch on the eukaryotic tree, because it has members in most of these branches except for parasites and poorly sampled genomes. CYP97 is beginning to emerge as another cross-kingdom P450. It is seen in plants and diatoms, but not outside of this clade. A third p450 CYP61 acts after CYP51 in the ergosterol biosynthetic pathway. It is seen in all fungi, but not outside fungi.To follow the evolution of the P450s in Deep time, we will need more completed genomes from some of these branches. Right now the only branches that are covered are anaerobes and parasites that have no P450s and plants. We will have to wait on Tetrahymena, Phytophthora and Trypanosoma to fill in some of these gaps. In the meantime, the top of this tree is better sampled. By looking at Dictyostelium and Fungal genomes, compared to plant and animal genomes, we begin to see some patterns. As the early lineages branched off from one another, there were very few P450s in common that have been retained as recognizable families. CYP51 is the only one that crosses all main divisions and CYP97 seems to be limited to the plants/alveolates/stramenopiles clade. Aside from these, each major lineage has done its own independent evolution of p450s. Dictyostelium has at least 46 P450s. Only CYP51 is found in common with other lineages.
Fungi are very diverse. The first eukaryotic genome Baker’s yeast (shown here) had only three P450s a CYP51, a CYP61 and CYP56. The first two are in the ergosterol pathway of all fungi, the last is a spore wall maturation gene specific to yeast and some close relatives (probably including candida). So yeast could be considered a minimalist P450 genome. S. pombe is even more minimalist, since it has only CYP51 and CYP61. Neurospora on the other hand has 38 P450s. This is a lot for a single celled organism and it blew the assumption that fungi would have very few P450s. However, the real surprise in fungi was the white rot genome. Phanerochaete chysosporium appears to have about 150 p450s. White rot is a group of wood degrading fungi. They break down lignin, which is brown leaving behind cellulose which is white, thus the name white rot. Without this type of fungi, the planet would be covered with lignin, a very complex aromatic ring based polymer. This genome is being sequenced at the Dept. of Energy Joint Genome Institute in Walnut Hill California as part of a microbial genome initiative. The fungus can grow at the high temperatures found in wood chip piles, making it a potential industrial agent for bleaching paper pulp instead of the polluting acid or base chemistries that are currently used. The fungus secretes many oxidative enzymes including peroxidases, and may be useful in bioremediation of toxic waste sites. The concept of fungi as environmental clean up agents is shown here. This slide shows a mushroom taking a bite out of a chlorinated and hydroxylated ring compound. The picture was taken from Thom Volk’s Fungus of the Month web site, which has detailed write ups on dozens of fungi along with some exceptional photos.
{kind=link}
{kind=link}
I began searching the white rot genome expecting it would have a few P450s, maybe 10-15, but I was very surprised by the large number of hits. After doing multiple searches with a variety of P450s and assembly of overlapping fragments, I was left with 167 contigs. So far I have assembled 103 genes with all intron-exon boundaries identified and I have 64 more to do. 96 of the 103 sequences are full length P450 genes. I expect when all assemblies are done that white rot fungus will have between 130 and 150 P450s.
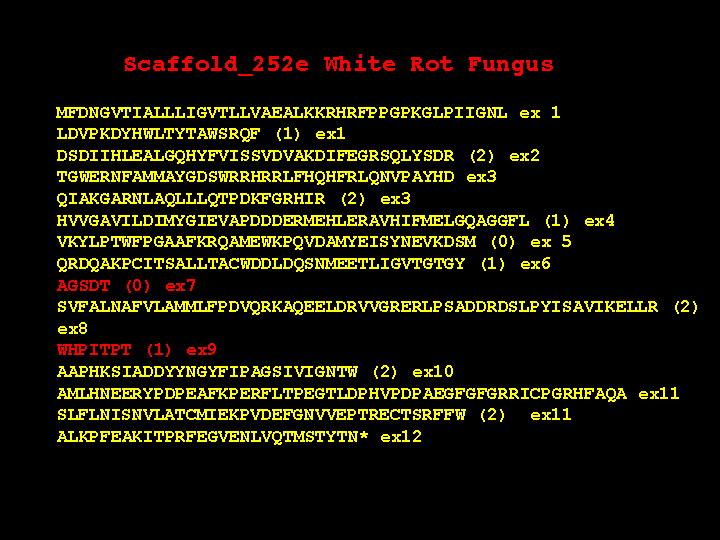
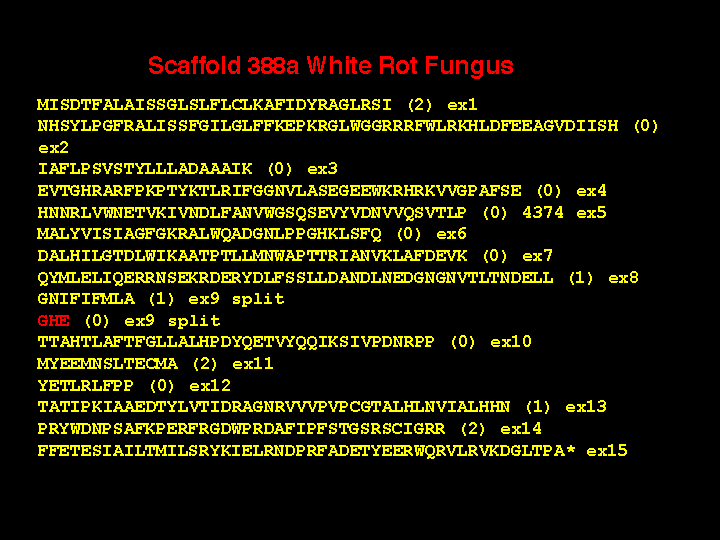
The white rot genes have many exons with short introns separating them. There are also some unexpected features. This slide shows the structure of one P450. This gene has 12 exons. Please notice the red ones are very short. What is the evidence that these are real? First, the end of exon 6 is phase 1, while the beginning of exon 8 is phase 0. You cannot join these two exons together without an intervening exon with phase 1 and phase 0 ends. Exon 8 and 10 have a similar problem. Second, there are 28 P450 genes in white rot that have this same exon structure. Third, the AGSDT sequence is the highly conserved part of the I helix oxygen binding pocket. Without this exon, this five amino acid motif is clearly missing from sequence alignments with other P450s, so it must be there in the gene someplace. The short exon 9 is also missing in alignments right after the EXXR motif.
{kind=link}
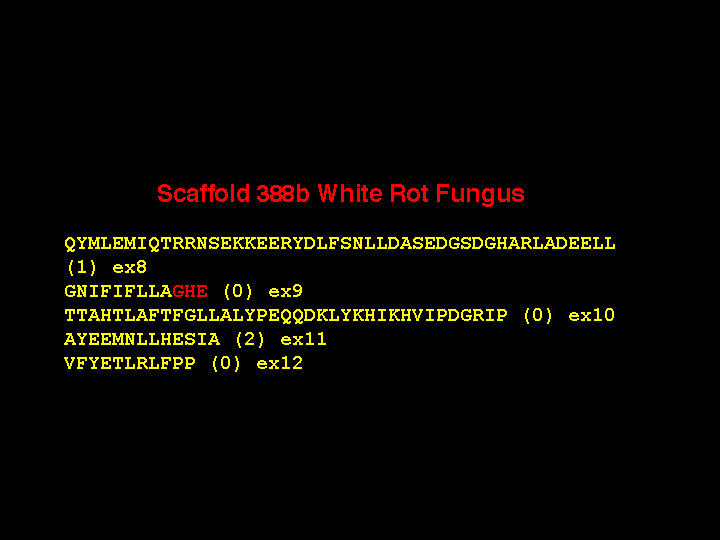
There are two other 5 amino acid exons at different locations in some of the white rot P450 genes, but those are not the shortest exons. Here is a gene with a three amino acid exon (actually 8 nucleotides long). Again, the phases are incompatible from exon 9 to 10, requiring an intermediate exon, The sequence is in the same region as before at the AGHETT conserved site in the I-helix and there are six P450s with this same intron-exon structure. As further evidence I offer this sequence from an adjacent gene where exon 9 is not split and the GHE sequence is on the end of exon 9. These short exons make the gene assembly process difficult. They also adversely affect automated gene assembly programs that probably cannot detect them.
{kind=link}
{kind=link}
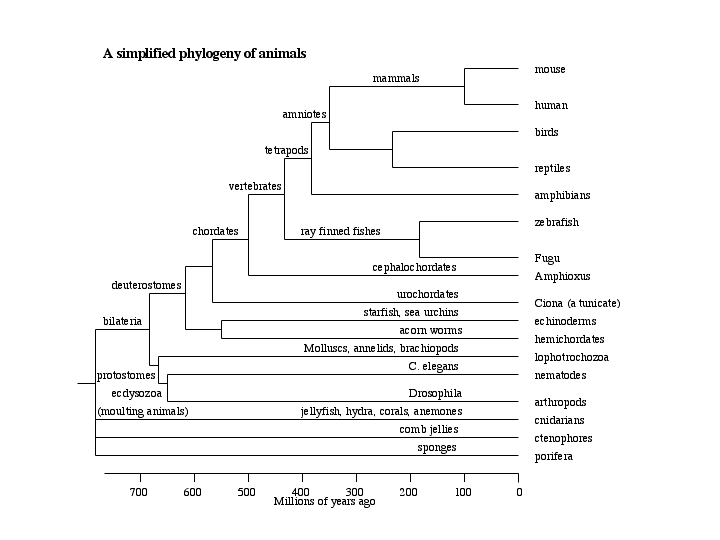
Our previous eukaryotic tree showed animals as a single branch on the top of the tree. However, animals are quite complex as shown here . At the bottom, there are the sponges, followed by the radial animals. We have no genomes for any of these, but I am sure they will be done. Above the radial animals are the bilaterians, which get split into two main groups, the protostomes (mouth first) and the deuterostomes (mouth second), which is a major distinction in development of the embryo.
{kind=link}
Drosophila and C. elegans are in the protosome groups, but for now we will concentrate on the deuterostomes. The lowest branch includes echinoderms, the sea urchins and sea stars. EST projects are underway on sea urchins, but they are not very extensive yet. Above the echinoderms are the tunicates also called urochordates. Above the urochodates are the chordates proper. These include the ray-finned fish and tetrapods (that includes us) that diverged about 420 million years ago. The urochordate group is the sister group to chordates, branching about the time of the Cambrian explosion 540 million years ago. Two genomes of the genus Ciona have been sequenced. Ciona is a sea squirt. Sea squirts are filter feeders that have a larval stage that looks like a tadpole, with a visible notochord. These larvae swim for a while then settle on the sea floor and assume the adult form. This is Ciona intestinalis, sequenced by the Joint Genome Institute (the same people who did white rot). A second species, Ciona savignyi has been sequenced by the Whitehead Institute. Their proteins are about 70% sequence identical, less than mouse and human, so they are quite different. I have used the Ciona genomes in teaching a bioinformatics class. We collected about 800 sequence reads containing P450 sequence from the JGI genome data by blast searches. These were translated and assembled into about 200 contigs. The last assignment in the class was to assemble a P450 gene from these contigs and the raw sequence reads at JGI. I must say the students struggled with that assignment. Not one student was able to assemble a complete gene. Only 24 Ciona p450 genes are assembled so far, some from each species. I can say from sequence alignments of the heme signature region that there are at least 60 different P450 genes in Ciona.
{kind=link}
{kind=link}
When I was in Japan in July for the MDO2002 meeting, we traveled to Ise and visited Mikimoto Pearl Island, where the famous pearl culturing company is located. After just spending weeks on looking at the Ciona genome with my students you can imagine how surprised I was to see this in the pearl museum. Ciona intestinalis is a pest to the pearl industry because they like to grow on the oyster shells. They have to be cleaned off once a year.
{kind=link}
It is still too early to do much comparative genomics on the Ciona P450 sequences, because we do not have a complete set assembled yet. They have been much harder to do than expected. We do have a nearly complete set for the Fugu genome. Fugu is the Japanese pufferfish. It has been sequenced by several labs including JGI again. Last October JGI assembled the genome. I have done an extensive anlaysis of the Fugu P450 genes by blast searching with members of every mammalian P450 family and some of the subfamilies. After all the searches were done the resulting list of accession numbers is nearly comprehensive, at least for the most conserved regions of the P450s, especially the heme signature region.
{kind=link}
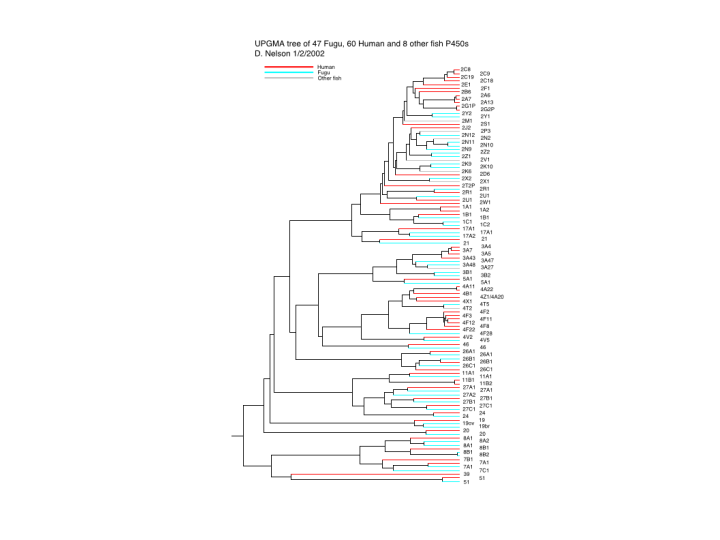
The alpha list of accession numbers had 332 hits after this process. This is smaller than Ciona’s 800 because the genome sequence had been assembled. The contigs are larger and there is not the redundancy of coverage. The translated protein sequences were put in a blast server and each sequence was compared against each other sequence for exact matches. These were then combined into contigs. Right now there are 71 contigs from Fugu P450s. 35 of these are full length genes and 12 are missing only small pieces. These 47 sequences were put in a sequence alignment with all the human P450s and 8 other fish sequences. A phylogenetic tree was constructed to compare the Fugu and human proteins. . This is the result.
{kind=link}
Human sequences are in red, Fugu in blue. If you look at the bottom of the tree first, you will notice an alternation of red and blue branches. This is equivalent to saying there is nearly a one to one correspondence between Fugu and human in their P450s. In the middle region of the tree this one to one arrangement starts to break down at the subfamily level. Here there are new subfamilies in one species that are not in the other. Notice the 4A, 4B, 4X and 4Z in humans and only 4T in fish. Also see the six 4Fs in humans and only one 4F28 in Fugu. At the top of the tree, the relationship breaks down almost completely. This is the CYP2 family. Many CYP2 sequences in humans are involved in metabolizing drugs and foreign chemicals. This has allowed diversification of the CYP2 subfamilies.
To make the relationships easier to see, I have drawn some figures that link the families and subfamilies together. The first of these shows just the CYP2 family. Humans have 13 subfamilies, while Fugu has 8. Only 2 of them are preserved across the 420 MY of evolution. These are the CYP2R1 and CYP2U1. There are no publications on these P450s yet, so we do not know what they do. Because they are conserved between fish and man, I would predict that they metabolize endogenous substrates rather than foreign compounds. This suggests they might also be implicated in disease.
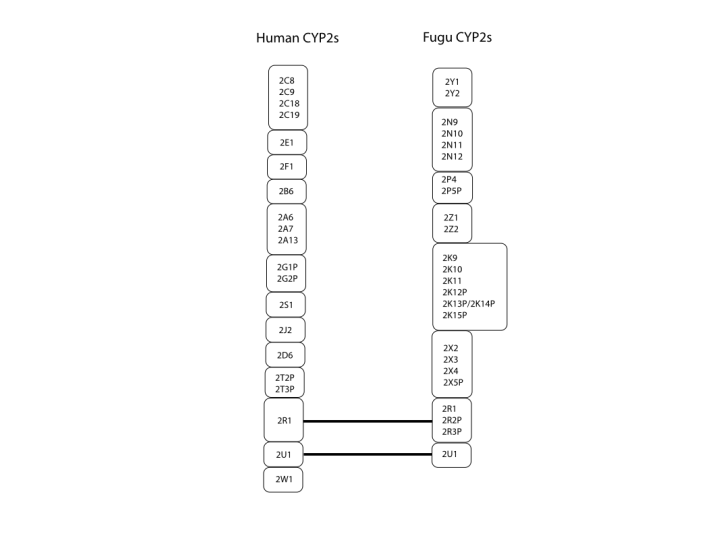{kind=link}
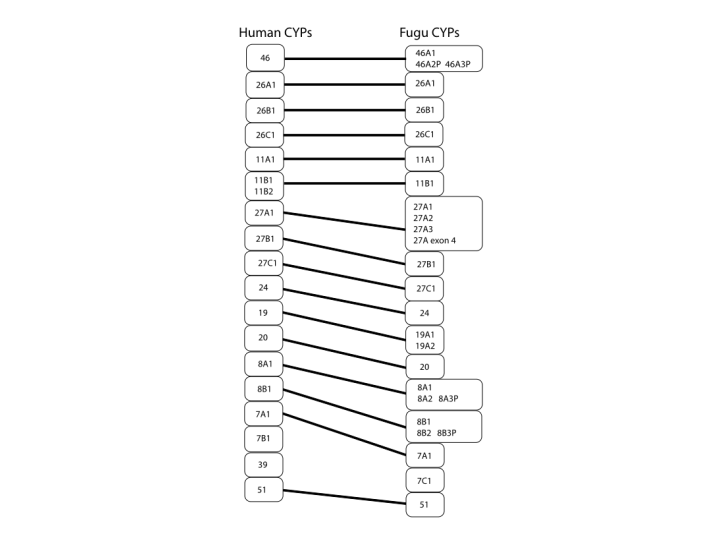
The next figure covers the middle region of the tree. Here we see the 4 family again with 4A, B, X and Z as possible diversified subfamiles coming from the 4T subfamily in fish. There are also 1C and 3B subfamilies in Fugu that are not seen in human. One other item in fish that comes up several times is expansion of familes that only have one member in humans. This is seen here in the CYP17 sequences. The third figure covers the bottom of the tree and we see very clearly the one to one relationship between families and even subfamiles that goes all the way through the two species P450s. There is only one exception at the family level and that is CYP39. This sequence cannot be found in Fugu. You might say that the genome is not quite complete and it might be found. That is possible, but I have also looked for CYP39 in zebrafish and every other fish cDNA and genomic sequence in genbank with no luck. I suspect that this is the one innovation that is new to mammals.
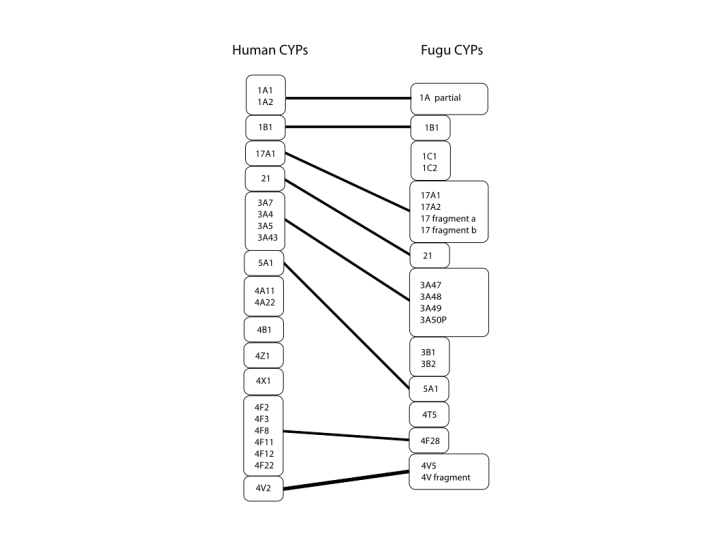{kind=link}
{kind=link}
[Note added in 2004, CYP39 has been found in fish now]
Note that CYP19, CYP8A and CYP8B have two sequences in fish and only one in human. Also, CYP27A has three fish sequences and one in human. Combined with the CYP17s seen before, these may be relics of a complete genome duplication in fish that did not happen in tetrapods. Evidence for a fish genome duplication is found in the Hox genes. Fish have 7 clusters of hox genes, while mammals have only 4. These are all on different chromosomes, so it looks like the whole genome duplicated and then one hox gene cluster was lost. P450s that were present at the time of this duplication should also have been duplicated. That, in combination with gene loss might explain the odd sets of duplicate fish P450s that have only one copy in humans. It will be useful to compare Fugu with zebrafish when that genome is more complete to see if the gene duplications are in both fish genomes.
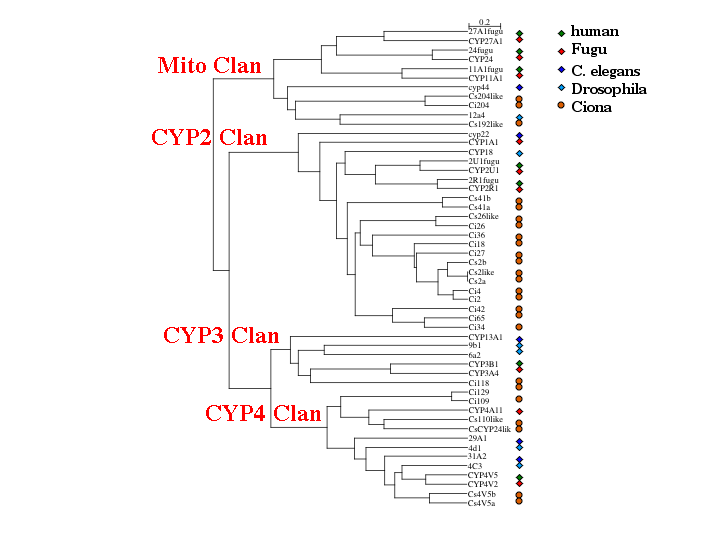
Fish and humans are remarkably similar even after 420 million years, but this is not true for Ciona. With 24 complete sequences to work with I made this phylogenetic tree on Tuesday. This includes 13 Ciona intestinalis sequences and 11 Ciona savignyi sequences. A mixture of human, Fugu, Drosophila and C. elegans sequences were added to sort the new sequences into clans. Clans are groups of P450 families that always cluster together on trees, so they are like gene clades. The genes have color coded species symbols on the right. The four major clans are represented on this tree. After looking fairly hard for a CYP51, no CYP51 like sequence could be found in Ciona. It seems to have lost that gene. Drosophila and C. elegans have also lost CYP51. Apparently it is not required if you can eat sterols in your diet.
{kind=link}
What this tree shows is that the common ancestor to the bilateral animals had at least these four clans of P450s represented, plus we know CYP51 had to be present, since it is found in both lower and higher eukaryotes. That is a minimum of 5 P450s at the time of the protostome deuterostome divergence about 670 million years ago.
{kind=link}
We can also see that Ciona is expanding the CYP2 Clan. It is common for one lineage to expand one or two clans to meet its P450 needs. This is shown here for C. elegans, where half of the C. elegans P450s also are in a single clan that is related to the CYP2 clan.
{kind=link}
{kind=link}
My last slide is just a pretty image of some more sea squirts. We have to do more work to finish assembling about 100 more P450 genes from the two Ciona species. Only then can we know about the relationships to other P450 families found in the vertebrates. This may shed some light on the origins of steroidogenic and retinoid metabolic pathways in these organisms.
{kind=link}