Awaji Island, Japan talk August 2, 2004
P450 Monogatari
David R. Nelson
University of Tennessee, Memphis, TN 38163
Abstract (expanded)
P450 monogatari translates as Tales of P450, usually an epic story across generations.
The scale of P450 sequencing continues to expand with over 3800 named P450
sequences and more coming every week. Though mammalian P450 diversity has been
largely saturated, plant and insect genomes are showing that we have not found all
families in these phyla. Fungi and Bacteria have every third or every other sequence in a
new family, so the potential diversity there has not even begun to be sampled. This is
exemplified by The recent sequencing of sea water samples from the Sargasso Sea.
Today we are getting a better look at early P450 evolution by characterizing sequences
from Hydra, a Cnidarian and Cyanidioschyzon merolae, a 16Mb red algal genome with
only five P450s, A CYP51, two CYP710s and two others, not related to known plant
families. Since CYP710 is found in Chlamydomonas also, this result emphasizes the
importance of this P450 in plant biology, but we do not know its function. The hydra has
a partial sequence with best matches to CYP20 sequences from mammals, fish and Ciona
(sea squirts). The fundamental role of CYP20 may be related to developmental signaling.
More work needs to be done on this critical P450. Finally, unconventional methods may
shed light on P450 regulation. A recent analysis of 32 recombinant inbred strains of mice
by microarray shows potential genomic regions that could influence P450 gene
expression. In one case, a candidate gene is found in an extremely significant QTL
(quantitative trait locus) region that influences the expression of cyp2b10 (or Cyp2b
transcripts that cross-hybridize to the microarray). This region includes the gata1 gene, a
known developmental transcription factor involved in blood development. These
experiments were done in hematopoietic stem cells, a tissue where gata1 is essential for
differentiation into erythroid cells. Cyp2b10 or a related Cyp2b in mouse may be
involved in this developmental role. Cyp2b10 and human CYP2B6 both have a gata1
binding site upstream of the coding region.
My opening slide (1) contains 35 eukaryotic organisms for which a genome sequence is known or a sequencing effort is underway. Each of these has a link on my home page, which takes you to the information about the P450s in that organism. The set is not complete, as more genomes are being added all the time. This slide is intended to show the beauty of what we, as biologists, are attempting to understand. The newest organism added to this collage was the silkworm, [above the tomato] with both a Japanese led and a Chinese genome project. (2) Here we see an Ukio-e print of silkworms being raised, and another (3) of the silk being spooled off from the cocoons, in this traditional Japanese enterprise.
{kind=link}
{kind=link}
{kind=link}
Perhaps, with less artistry, but more detail, my homepage has nearly doubled in recent months (4). Many new species have been added, including honeybee, Hydra, silkworm and red algae. Rene Feyereisen has given us a fascinating summary of insect P450s. Later, I will come back to Hydra and red algae. As we move down in the page we come to the lower eukaryotes and bacteria. This group has just exploded recently. Notice every date in red except one is from 2004 and half are from June and July.
It has become customary when I talk to give a summary of the P450 gene count and progress in sequencing. (6) This graph shows the history of P450 sequencing, starting in 1982 and taking off in 1996 after the yeast genome was completed. The main eukaryotic genomes released are listed above the line. Once more, I cannot put all the genomes on this slide since there is not enough room. The total named P450 count is now 3811 and will exceed 4000 by year’s end.
{kind=link}
If we break the sequences down into 5 major groups, (7) we find about 40% are from animals, 30% are from plants. About 12 to 13% each are from fungi and bacteria and only 5% are from protists, though the protist sequences may be the most interesting from an evolutionary point of view.
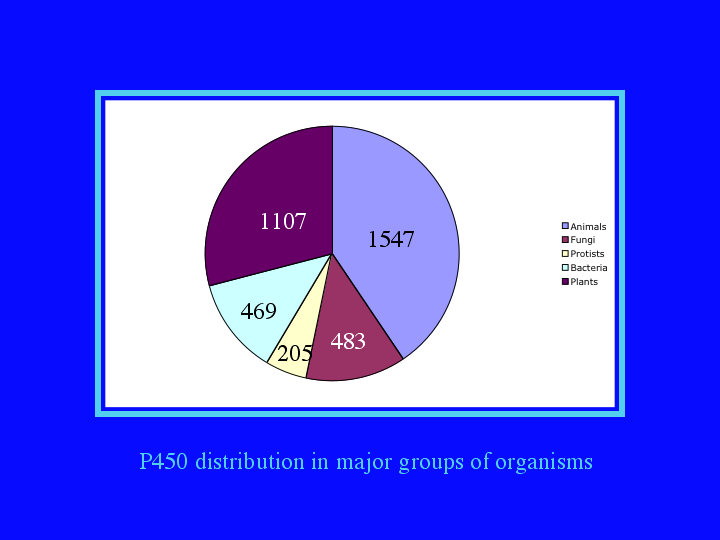{kind=link}
Another way to display this information is on the tree of life (8).Plants, animals and fungi are well represented. Even bacteria have many sequences, with many more waiting to be named. A P450 has even been found from a strict anerobe. CYP152A2 is from Clostridium acetobutylicum, though it looks like a lateral gene transfer, since CYP152A1 is a peroxygenase from Bacillus subtilis. [extra slide showing CYP152A1 at the very top of this bacterial tree] The archaea have only 6 P450s and at least one of those looks like it came from another lateral gene transfer. When I gave a talk in March, these 80 sequences were only 6. (9)The 74 new ones have come from three stramenopiles, two Phytphthora genomes and a diatom genome sequenced at the Joint Genome Institute. Phytophthora ramorum, pictured here, is the Sudden Oak Death organism that is killing oaks in California. (10)Also in March, I did not have these 70 ciliate sequences. (11) They are from Tetrahymena thermophila , with 48 P450 genes and Paramecium tetrauralia with 22. Even though they are both ciliates, they do not share any P450 families. (12) Ciliates are alveolates, a group that includes Apicomplexan parasites like malaria.
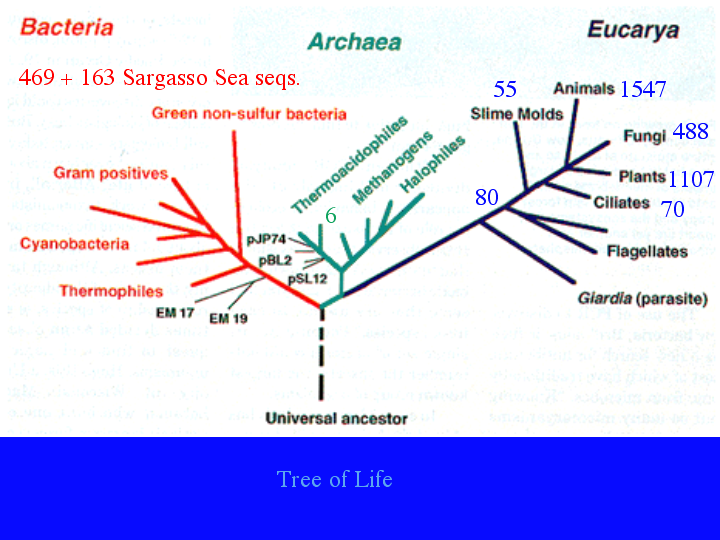{kind=link}
![[extra slide showing CYP152A1 at the very top of this bacterial tree]](https://drnelson.uthsc.edu/japan04talk/slide38.png){kind=link}
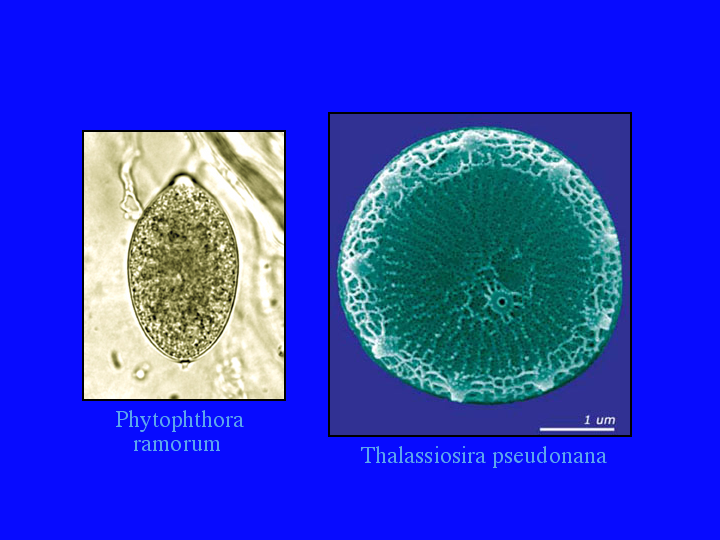{kind=link}
{kind=link}
{kind=link}
{kind=link}
In this tree, a red X indicates the presence of P450s. Red species names have completed genome sequences. Blue indicates a sequence project is underway. When the malaria genome was sequenced, I was surprised to find no P450s in the genome. This is probably the consequence of a parasitic lifestyle, allowing Plasmodium to streamline and dump uneeded genes. At the time, I made a prediction that free- living relatives like Tetrahymena and Paramecium would have P450s, at least CYP51, required for making sterols, since all eukaryotes need sterols for their membranes. However, I was proved wrong. These organisms do not have CYP51, indicated by the – CYP51 label. All of their P450s seem to be derived from one common ancestor related to the CYP3 and CYP4 clans. Surprisingly, Tetrahymena can be grown in a defined medium without sterols. So the claim that all eukaryotes require sterols is too simple, but what do the ciliates use instead? The solution to this problem is that Tetrahymena makes a molecule called tetrahymanol and Paramecium makes hopane. (13).These pentacyclic triterpene compounds work in place of sterols, and they do not require oxygen or a P450 to synthesize them. CYP51 removes the 14 alpha methyl group from this location in sterol precursors, but this methyl remains in tetrahymanol and hopane. CYP51 has been found in a diatom, a stramenopile relative of the alveolates, so it looks like the ciliates lost CYP51.
{kind=link}
CYP51 has been found in four bacterial species, (14)three Mycobacterium species and Methlococcus capsulatus. This tree shows 48 representative CYP51s and a new subfamily nomeclature to address their broad diversity. This figure is from our paper in the June issue of Plant Physiology comparing Arabidopsis and rice P450s. Subfamilies have been added to the CYP51 family so that major taxonomic divisions have subfamily rank. The top shows animals as CYP51A and fungi as CYP51Fs. Plant CYP51s are in Green, including a large number of unusual rice CYP51s called CYP51H that probably have a new function. The orange CYP51D sequence is from Dictyostelium and the purple CYP51Es at the bottom are for euglenid CYP51s like Trypanosoma and Leishmania. The evolution of CYP51 is taking on some importance for arguments about the evolution of eukaryotes. Tom Cavalier-Smith, one of the formost authorities on early evolution in eukaryotes has siezed on this information to argue that Actinobacteria, high G+C gram positive bacteria, that includes Mycobacterium, were the precursors to eukaryotes. This is based, in part, on the presence of CYP51 and its critical role in making sterols, a eukaryotic hallmark.
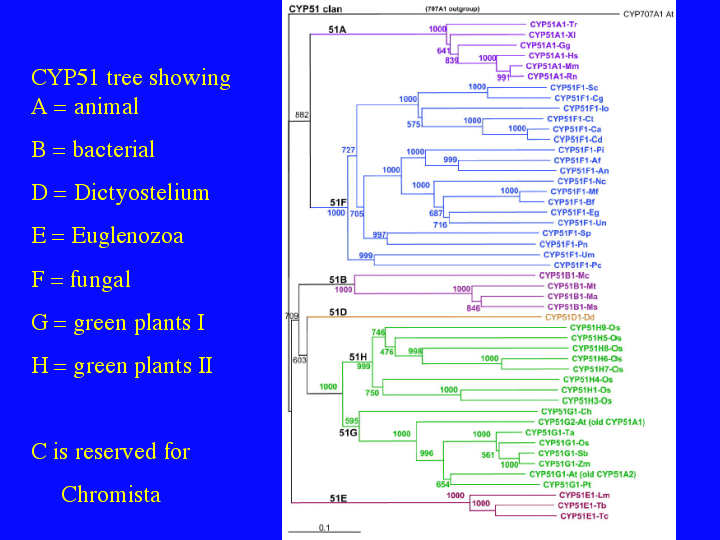{kind=link}
However, Damjana Rozman has pointed out that a tree of CYP51 sequences shows another possibility. The bacterial CYP51s cluster together inside the eukaryote CYP51s with high bootstrap support (709/1000 trials). This is not what one would expect if bacterial CYP51s were ancestral. They should fall outside the eukaryotic branches on the tree. Damjana argues that the Mycobacterium CYP51s are plant- like, prefering obtusifoliol as a substrate as in plant CYP51s, plus they cluster with the plant CYP51s. She proposed that they are a lateral gene transfer from plants to bacteria and the bacterial CYP51s are not precursors of the eukaryotic CYP51s. This argument seems very probable to me and it moves the origin of CYP51 inside the eukaryotes, not in the bacteria. That is what makes the tetrahymanol story interesting. Where did CYP51 first appear. It will take more sequences to answer that question.
[Note on the discussion: Steve Kelly pointed out that CYP51 is not the only enzyme involved and at least in M. capsulatus the lanosterol pathway is present. This is much harder to explain by lateral transfer.]
Fungal genomes
Scott Kroken was originally a scheduled speaker in this session. He was going to talk about P450s in fungal genomes. His company, XXXXXXXXXXX, would not allow him to present his data here, since they claimed it was proprietary. He had analyzed all the P450s in three fungal genomes sequenced by Syngenta [Cochliobolus heterostrophus, Botrytis cinearia, and Fusarium verticillioides]. I have done a similar analysis on four fungal genomes, all different from the three he did. I would like to show just three slides to comment on the enourmous diversity of fungal P450s. There are almost 500 named fungal P450s, so I cannot show them all, but I will show you a master fungal P450 tree and then we will zoom in and look at two branches in more detail. All of these trees are posted on my website. Goto Trees (15)
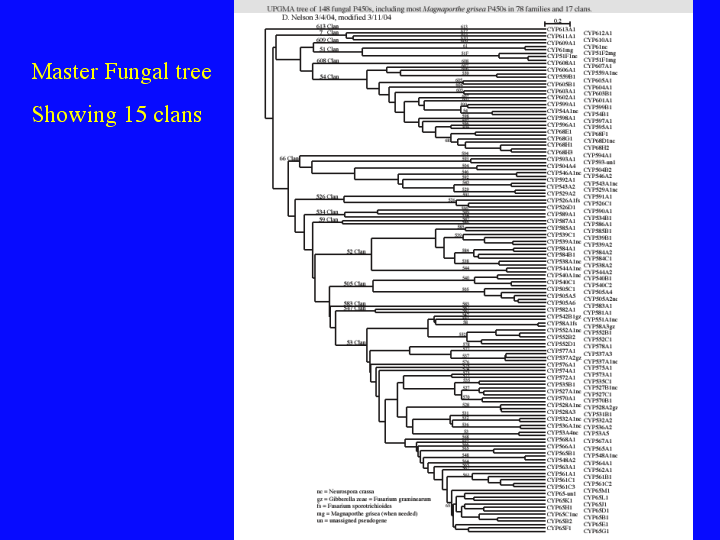{kind=link}
Here is a tree with 148 sequences representing 15 different P450 clans in fungi. Most of these sequences are from Magnaporthe grisea, but others have been added to try to make it a representative tree. I know you cannot read it, but that is not important. Notice the vertical lables down the middle. These are the family names. There are 77 families named in this tree. After I had already done three genomes, I started to work on Aspergillus nidulans, thinking most P450s would fall in existing families and it would be easy to name them. This was far from the truth. There were 111 P450s in Aspergillus nidulans, and 49 of them belonged to 42 new families. That is 44% or 4 out of every 9 sequences were in a new family. I suspect this will continue for quite a while.
The sequences fall into clusters or clans on this tree. Let us look at two of these branches. (16)The first is the CYP7 clan. It has only three sequences in the master tree, but if we look in detail, we see 28 sequences in 21 different families. The interesting feature of this clan is the CYP7 andf CYP8 animal families fall inside it.
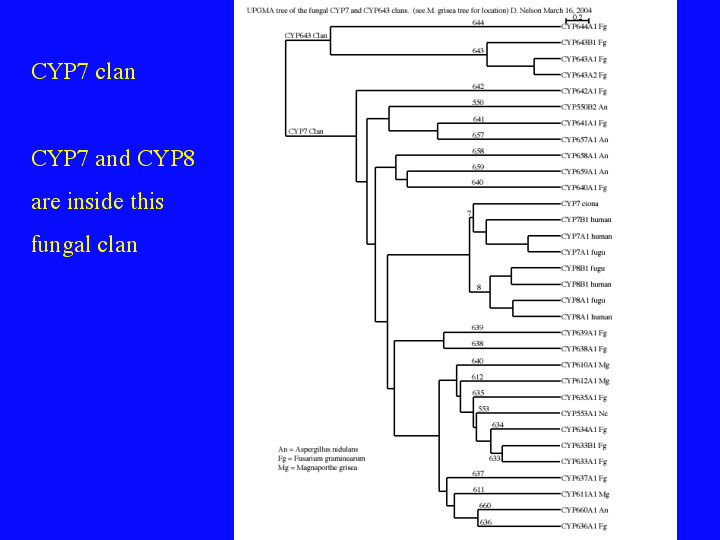{kind=link}
The next slide (17) shows the CYP505 clan. CYP505A1 is P450 foxy, a P450 fused to an NADPH P450 reductase domain like CYP102 or BM3 from Bacillus megaterium. All the CYP505 sequences have the same fusion structure. At least one of the CYP540 sequences also has the fusion, but not all CYP540 or CYP541 sequences are fused. I think it is clear from these trees, that we are only beginning to sample the sequence diversity of P450s in fungi.
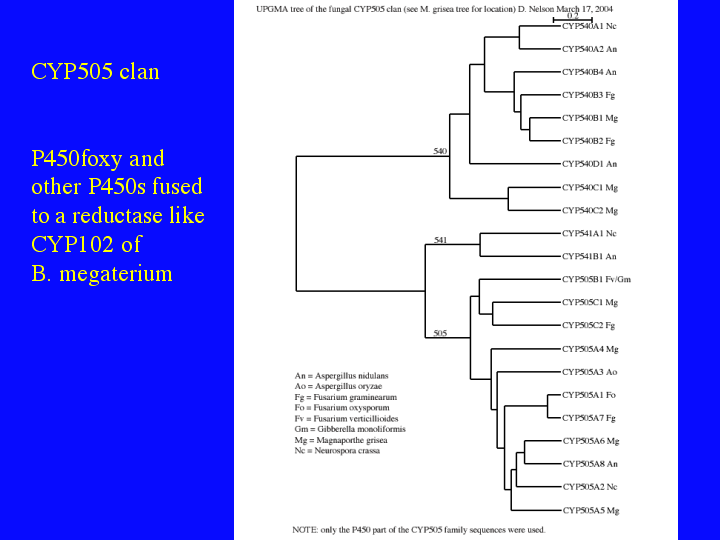{kind=link}
Bacteria are even worse. Almost every other sequence from bacteria is in a new family.
Now I would like to move on to plants. (18) Even though plant P450s were relatively late comers with the CYP71A1 sequence from avocado published in 1989, we now have over 1100 named plant P450s. Two thirds of these are from two species, Arabidopsis and rice (19).Plant P450s make up about 1% of all the genes in plant genomes. In rice alone there are an estimated 356 functional P450 genes and about 100 pseudogenes. Since there are nearly 275,000 named angiosperm species, There are over 50 million plant P450s.
{kind=link}
{kind=link}
That sounds hopelessly complicated, but this large number of individual sequences sorts into about 60 CYP families. These can be even further ranked into just 10 plant P450 clans. (20)This slide shows the plant P450 families sorted into clans. Note that 6 of the 10 clans have only one family. The other four are larger. As an example I show you the CYP86 clan, (21)showing 5 families in different colored blocks. CYP86A1, 94A1, 94A2 and 94A5 are fatty acid hydroxylases most similar to CYP4 in animals and CYP52 in fungi, which are also known fatty acid or alkane hydroxylases.
{kind=link}
{kind=link}
Work is being done all around the world on characterizing the function of these CYP families. It is going to be hard, because there is a lot of redundancy. CYP96A has 12 full length genes in Arabidopsis and CYP71B has 35. One way to get a handle on this great variety is to compare families across plant taxonomic groups. This slide (22)shows a map of plant P450 sequence space. The 62 plant families are listed across the top sorted by clan and the verticle axis shows plant phylogeny. This only includes angiosperms and one line for gymnosperms at the top. It does not include ferns, mosses, liverworts or green algae. Each dot represents the presence of that CYP family in that plant taxon. The two intense lines are rice (a monocot) at the top and Arabidopsis (a dicot) at Brassicales. These genomes are complete. The others are only partial samplings by ESTs or genome survey sequencing. Fabales includes soybeans with 350,000 ESTs and Solanales includes tomato and potato each with more than 150,000 ESTs.
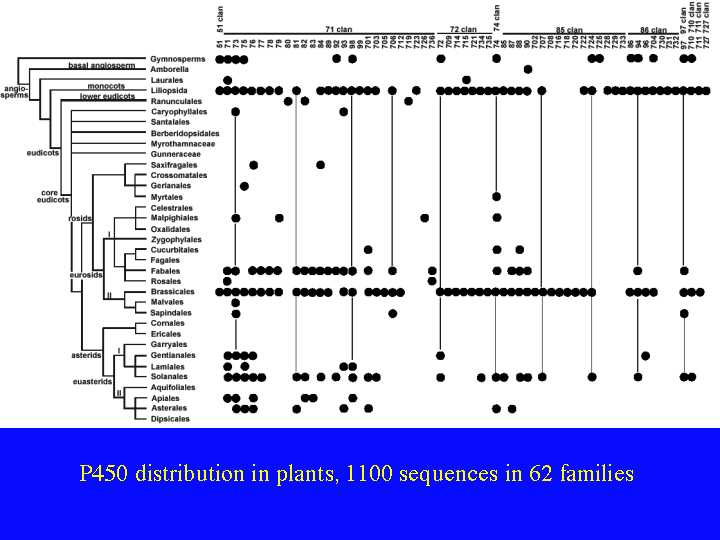{kind=link}
By comparing the dots between rice and Arabidopsis, we find 39 of 59 families are shared between one monocot and one dicot. That is two thirds of CYP families existed in the common ancestor about 200 MYA. This number may go up when more genomes are sequenced, because rice and Arabidopsis may not be completely representative of monocots and dicots. There is a lot of white space in this figure. We really need more genomes sequenced to sample the space more fully.
Gymnosperms (especially pine trees) have only been sampled by EST sequencing, but already one quarter of the plant P450 families and 8 of the 10 clans are found in these ESTs. CYP711 is found in chlamydomonas a green algae so it is expected to be in gymnosperms raising the number of clans to 9/10. The divergence date for gymnosperms and angiosperms is 360MYA, so much plant P450 biochemistry was already in existence that long ago. Once more, we need more sequences.
You can read about this in more detail in a special Arabidopsis issue of Plant Physiology that came out in June. Link to paper (24)
{kind=link}
One of the goals of my bioinformatics research on P450s is to understand the earliest evolution of the superfamily in eukaryotes. That is why Darwin was on the opening slide. The many new genomes are helping this process along. While examining the Trypanosoma cruzi genome for P450s, I found a fragment that seemed out of place. It was not present in three other Trypanosoma genome projects. I thought it was a contamination, until I found it in the Leishmania major genome. Both are euglenozoans, so it was not contamination. A blast search of the EST database hit another very curious sequence from a choanoflagellate. These cells are thought to resemble the ancesotor of all animals and they look just like the collar cells of sponges. This sequence had its highest scores in blast searches to CYP61 sequences in fungi, CYP524 in Dictyostelium and CYP710s in plants and red algae. (25)A tree with related sequences shows a new P450 clan, not previously recognized, the CYP61 clan. The ancestor of this sequence was in the precursor of all animals, fungi, plants (both red and green algae), Dictyostelium and euglenozoans. In other words, it is a very ancient eukaryotic P450, as widely disitributed as CYP51, but less conserved in sequence. CYP61 is a C-22 sterol destaturase involved in ergosterol biosynthesis also called ERG5. It is not clear that this function is preserved in CYP710 or CYP524 or the other sequences. No strong candidate matches these sequences in animals.
{kind=link}
CYP20
After naming thousands of P450 genes, a person develops some favorites. One of my favorites is CYP20. This is a gene found in sea squirts, fish and mammals (all chordates). Recently, a P450 sequence was found among Hydra ESTs (26) that had its best match in chordates to CYP20. (27)This sequence matched another sequence in a leech (which is an annelid worm). The leech sequence also appeared to be a CYP20 ortholog. (28)Halocynthia roretzi (or Maboya in Japan), which is another tunicate, has a clear CYP20 ortholog with 51% sequence identity. Surprisingly, a complete P450 from a sponge named CYP38A1, is also a best match to CYP20 sequences. (29)The presence in sponges, hydra, annelids and chordates means that CYP20 was in the common ancestor to all animals and it has been preserved over a billon years. A CYP20-like sequence is not detected in insects yet, though the function may be there, the sequence similarity is not. I have asked several people to try experiments on CYP20 to see if it does anything interesting. I finally found someone who said yes. Todd Penberthy was doing a postdoc in a zebrafish lab and was looking for some targets to knockdown with morpholino antisense probes. His lab was working on blood development, so they had a reporter strain of zebrafish with green fluorescent protein under the control of the gata1 promoter. Gata1 is a transcription factor important in erythropoesis. Normal fish would have typical levels of gata1 and they would express the GFP and make normal red cells. Fish with reduced gata1 would not make the normal number of red cells and they would not be green fluorescent. In fact, a mutant in gata1 produces the vlad tepes bloodless phenotype in zebrafish. Todd injected embryos with the morpholino antisense probe for zebrafish CYP20 or a sham injection with buffer and this is the result. (30, image held back for a publication) The antisense morpholinos greatly reduced the level of GFP in the treated embryos but not in the sham injected controls. Blood development was not turned off but it was reduced. The most dramatic effect was in the GFP expression in the eye and the lower part of the head. This result suggests that CYP20 is an upstream regulator of Gata1, a critical transcription factor in erythropoesis and possibly in the development of the eye. We expect CYP20 is acting on a lipid substrate to make or degrade a signaling molecule. This molecule may then bind a receptor protein and alter gata1 expression. Gata1 comes up again in an independent context. (31)To tell you about this I need to apologize in advance. I have to talk about mice. I know this is usually a non- mammalian meeting, but the mice offer a very unique method to look at P450s that just is not available anywhere else yet.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
We are going to talk about recombinant inbred strains of mice and quantitative trait mapping. Rob Williams at UT Memphis has created a web site called WebQTL (32) that allows one to enter gene names for about 8500 different mouse genes represented on Affymetrix mouse chips. The software will analyze microarray data from about 30 different recombinant inbred mouse strains. Each line on this pull down menu is a separate experiment. The result is a QTL map showing the strength of a relationship between the expression levels of your gene and about 700 intervals defined by genotyped markers spread out over the whole genome. If a gene is significantly contributing to the variation in expression levels of your gene on the microarray chip, it will show up as a spike in the QTL interval map near the location of the controlling gene. The stronger the influence on expression, the higher the peak on the map.
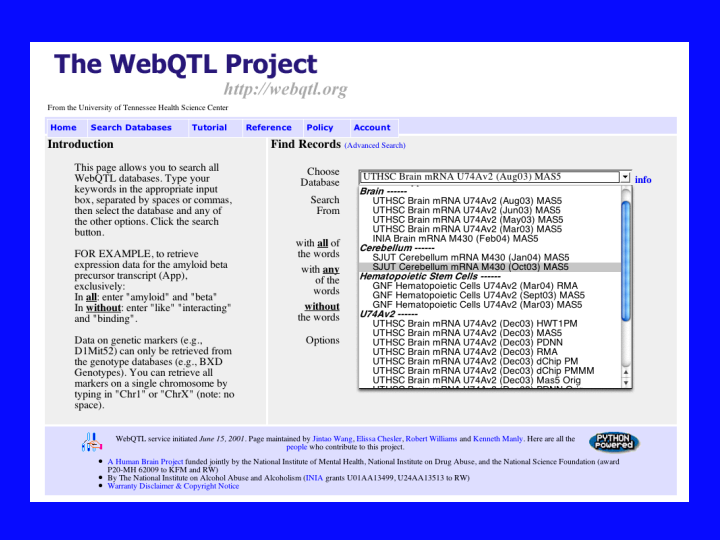{kind=link}
Rob has done microarray analysis on these 32 inbred strains at 3 chips per mouse for dozens of separate experiments. That is about 100 Affymetrix chips per experiment. These data represent thousands of chips. Most of these are from brain, but there are three sets from hematopoietic stem cells, done by others.
I searched for all P450s on these chips by a text search for CYP*. This resulted in 74 hits. After subtracting out cyclophilins and duplicates, there were about 40 mouse P450s on the chips. I ran all the mouse P450s that were present against 24 data sets on the server and found quite a few QTL peaks. The strongest result was for Cyp2b10, and it is shown here. (33).This data is from the three hematopoietic stem cells experiments. The numbers across the top are chromosome numbers. The dotted green line indicates the peak height for a suggestive QTL (p = .5), but it may be accidental. The dotted blue line is a significance threshold (p = .05). Peaks exceeding the blue line are probably real QTLs. These three peaks are all strong, but the third experiment is way above the significance threshold. The interpretation is that there is a gene in this region on the X chromosome that influences the level of Cyp2b10 (or a closely related Cyp2b) in hematopoietic stem cells. So now you must look at a list of the genes in this region.
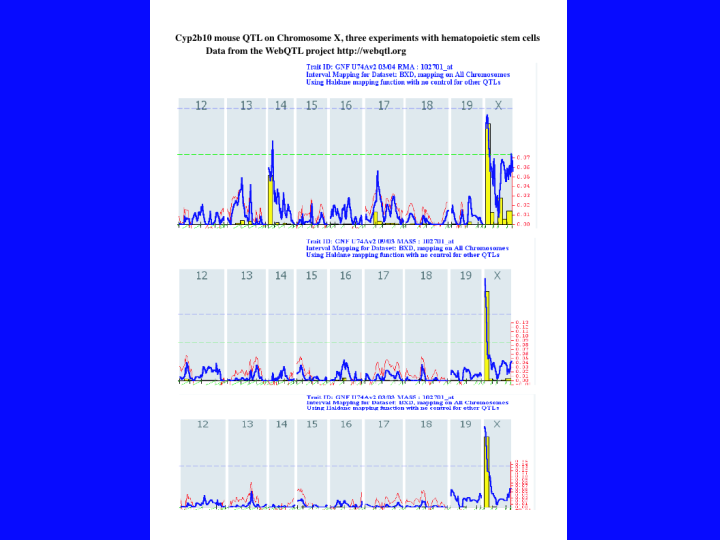{kind=link}
(34) This list is a partial list of the genes on the mouse X chromosome at the region of the QTL. One gene stands out as a strong candidate gene. Gata1 is a transcription factor required for erythroid differentiation, so it will be active in hematopoietic stem cells. A search of the mouse Cyp2b10 upstream region identifies a gata1 binding site. In fact, there are two of these sites in the human CYP2B6 gene. This does not prove that gata1 is the gene responsible for the QTL, but it creates a testable hypothesis. This may provide clues to the endogenous function of Cyp2b, independent of drug metabolism, a possible role in differentiation of erythroid cells.
{kind=link}
(35) This is a list of additional QTLs that were significant or appeared multiple times in independent experiments. I have not tried to go in and look for candidate genes for these QTLs. The QTL peaks are mapped only to a 10-15 Mb region, that can cover 150-200 genes. One interesting point is the cis QTL at Cyp8b1. This gene seems to influence its own expression in brain tissue. Cyp8b1 is a sterol 12 alpha- hydroxylase, so one can ask is there a cellular receptor for a 12 hydroxy-sterol in brain that can change Cyp8b1 gene expression? This QTL approach holds promise to identify upstream genes in P450 regulation. Most of the data so far is with brain, but liver is being done now, and that may be more useful for many P450s. The trick is going to be in identifying the best candidate genes and then testing them for effects on P450 gene expression.
{kind=link}
(36) We now return to our opening slide and hope you have enjoyed this first session. Thank you.